
Tags
Math puzzles always tickle the brain, and this one has tickled quite a few on LinkedIn. Why are these puzzles so popular, and what’s the right answer? I sampled 610 responses to find out.

Of the 610 responses I sampled, the range of answers was surprisingly large, although there were two clear candidates 98 and 99, followed by a less likely third, 101. The full table of counts looks like
x 2 27 40 71 81 82 88 97 98 99 100 101 107 108 113 119 263 1 1 1 1 1 1 1 4 268 293 1 17 1 4 1 10 4
According to the data, 48.1% of respondents said the answer is 99, while 43.9% said it was 98. If we trust the wisdom of the crowds, 99 is the correct answer, yes? Not so fast. This is what makes puzzles like this so popular because multiple plausible answers seem to exist. If there was a clear majority for a particular answer, the puzzle wouldn’t stoke the embers of our emotions. (Other puzzle constructions exist that use different strategies to draw people in.)
Why is 99 incorrect? People used a few different approaches to arrive at this answer. Let’s define a matrix 



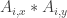
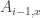
![[ 23, 47, 79, 99 ]](https://s0.wp.com/latex.php?latex=%5B+23%2C+47%2C+79%2C+99+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
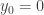
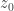
What about 98 then? Is this the correct answer? I saw two main approaches taken to arrive at this solution. The first defines the relationship 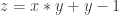
![z = [ 7, 23, 47, 79, 98 ]](https://s0.wp.com/latex.php?latex=z+%3D+%5B+7%2C+23%2C+47%2C+79%2C+98+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
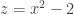
![[ 7, 23, 47, 79, 98 ]](https://s0.wp.com/latex.php?latex=%5B+7%2C+23%2C+47%2C+79%2C+98+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
So the lesson is that model builders and quantitative folks need to be ever vigilant of our own biases. Even if we come up with a solution that seems to fit the data, we need to think critically about the assumptions we are making and whether better, simpler models are out there.
Brian Lee Yung Rowe is Founder and Chief Pez Head of Pez.AI // Zato Novo, a conversational AI platform for guided data analysis and automated customer service. Learn more at Pez.AI.
R Code
x <- read.table('linkedin_math.txt')[,1]
table(x)
a <- matrix(c(3,2,7, 5,4,23, 7,6,47, 9,8,79, 10,9,NA), ncol=3, byrow=TRUE)
colnames(a) <- c('x','y','z')
# Yields 99 as final answer
sapply(2:nrow(a), function(i) a[i,1] * a[i,2] + a[i-1,1])
# Yields 98 as final answer
sapply(1:nrow(a), function(i) a[i,1] * a[i,2] + a[i,2] - 1)
# Yields 98 as final answer
sapply(1:nrow(a), function(i) a[i,1]^2 - 2)

I suspect I particularly liked this because I arrived at the z = x^2 – 2 relationship pretty quickly myself. I’ve also seen Occam’s razor referred to as the KISS principle; there’s certainly an elegance to simplicity.
LikeLike
Hey good for you 🙂 I was actually in auto-pilot mode so System 1 was in full force haha.
LikeLiked by 1 person
Do you mean that dependency across rows requires poor assumptions in general, or here specifically? Here, 99 is incorrect only because it doesn’t explain the sequence of X and Y. Had the final row been 11 and 10, then a recurrence relation taking row 1 as its seed would have worked perfectly well, without needing to infer any row 0. I’m also not sure that z = x^2 – 2 isn’t a bit lazy. It can’t be rearranged to explain y, whereas z = x * y + y – 1 can.
LikeLike
Specifically it’s a poor assumption but the point is to spend time thinking through the assumptions. In terms not using y in the equation, nothing says we need to incorporate y in the relationship. That’s like building a model and deciding whether or not to include a particular predictor. If you can explain the response without a variable, why include it in the model?
LikeLike
I might include it if it made the model more general. In this case, a new observation x = 11, y = 9, z = 107 would break the model z = x^2 – 2, but not the model z = xy + y – 1. The parsimonious model assumes that y is either totally spurious, or is directly related by y = x – 1, and those assumptions might be false. I think it’s always worth investigating whether a predictor offers no information at all, or merely no new information.
LikeLike
I know you said the answer is 98 if you consider the 2nd column as bogus. As I looked at the problem, my first solution had the 1st and 2nd column as bogus so the answer became 119. 23 = 7+8*2, 47=23+8*3, 79=47+8*3, 119=79+8*4
LikeLike
You guys forgot to use the old pattern recognition techniques, where if you follow the rule:
Find the next primer that is higher than the first number times the second number. If you do this the answer is 97…
LikeLike
But then 7*6= 42 would have used 43 as the next prime number (not 47)
LikeLike
Interesting.
I saw another pattern that doesn’t have a previous row dependency but gives 99 as an answer.
A(i, x) * A(i, y) + O(i) where O(i) is the ith odd number in the sequence 1,3,5,7…
This uses both the columns and there is no other row dependency. Is this not a better solution??
Thanks
LikeLike
I also came up with your way of trying to solve this riddle:
x*y + uneven integer (starting from 1)
Namely,
3*2 + 1 = 7
5*4 + 3 = 23
7*6 + 5 = 47
9*8 + 7 = 79
10*9 + 9 = 99
Even though I like our solution, we’re still depending on the row number in order to know which uneven number out of the sequence we’ll eventually have to add, thus making our solution not as parsimonious as propsed solution #2.
LikeLike
I thought the parsimonious solution was boring and wasteful. Leaving food on your plate is bad manners. It is much more interesting if you fill in ALL the blanks…and eat everything on your plate….so I believe the odd integer solution sequence is better because it cleans the plate.
I would not want to buy dinner for a parsimonious person.
LikeLike
10*9+ (10-2)=98
LikeLike
3+2=5+2=7
5+4=9+4+7+3=23
7+6=13+6+23+5=47
9+8=17+8+47+7=79
10+9=19+9+79+9=116
I thing this also Correct answer
LikeLike
To play the devil’s advocate on choosing model “x^2 – 2” b/c occam’s principle:
The reason people correctly prefer a solution with both x & y over a solution with just x, is because the joint x,y solutions are more parsimonious with human communication — these models are consistent with Grice’s maxim of quantity, “where one tries to be as informative as one possibly can, and gives as much information as is needed, and no more.” The problem-solver assumes that the problem-giver won’t give any additional information unless it is necessary to do the problem. Because the giver provides the additional column for y, the solver should correctly assume that it is a necessary part of the problem.
This is really quite interesting psychological/behavioral data – the op should post the data…
LikeLike
I ran symbolic regression using genetic algorithm, and the answer kept on fluctuating between the (y-1+xy) and (xx – 2). For example, on of the equation the program predicted was:
.-
..if
…76.0
…y
…42.0
..-
…>
….21.0
…./
…..27.0
…..86.0
…*
….y
….x
This translate to (y-1+xy).
Also, if you allow the program the use trignometric function, if/else, while etc, one can get even more number of solutions.
LikeLike
You could also say that:
z = x*y + (x – 2)
Then the results will be completly different for different numbers.
I find amusing that people see this as a logic problem, this is just an under specified problem, in which you can fit multiple models.
And, seriously, it is ridiculous to say that z = x^2 – 2 is a better model due to occam’s razor.
For that matter, why don’t we say that this a sequence of the form:
z_1 = 7
z_i = z_(i-1) + i*8
So the sequence does not depend on x and y whatsoever.
LikeLike
An engineer might call it overdeterminant. Too much data…not enough unknowns.
LikeLike
The correct answer is actually 119. The last column is the question, i.e. you’re doing a simple number sequence. The terms are generated by 7 + k*8, k = 0,2,5,9,…
LikeLike
Great article, thanks for sharing this information
LikeLike
This is an array a(ij) with dimensions mx3, so i belongs to [1…m] and j to [1…3]. Subsequently we can re-express this array as [ai1 ai2 ai3], so the formula for each entry is [i i-1 i^2-2]. For i=10, the entry a(10|3) has the value of 98.
LikeLike
Mmm. I have been looking at this and it feels like the answershould be 97.
= X^2 – (LCD of second number)
Other wise what is the purpose of the second number?
LikeLike
The answer is 98 and 99 also. (a×b)(b-1)
(3×2) +(2-1)=6+1=7, (5×4)+(4-1)=20+3=23, 7×6+6-1=52+5=47, 9×8+8-1=72+7=79, 10×9+9-1=90+8=98 the answer is 98. 3*2+ 1=7,5*4+3=23,7*6+5=47,9*8+7=79,10*9+9=99answer is 99.
LikeLike
Took me 15-20 min 😦 i’m so dumb
I used
(A+2)*B-A=…
(10+2)*9-9= 99
I’m so dumb 😥
LikeLike
3*2 = 7
2 ——— 16
5*7 = 23 8
2 ———- 24
7*6 = 47 8
2 ———– 32
9*8 = 79 4
1 ———– 20
10*9 = 99
7+16=23
23+24=47
47+32=79
79+20=99
The only logic is the sequence between them from the beginning to the end
The answer is definitely 99
LikeLike