
I’m creating an AI moderator for social media using reinforcement learning. The goal is to reduce toxicity/outrage and increase civility in online interaction.
Traditional social media rewards users with likes and followers. Research shows that people learn to maximize these rewards by posting highly polarized content, typically manifesting as moral outrage.
Negative polarization can be characterized by trolling, abuse, toxicity. Positive polarization manifests as enabling or apologetic content. Both tend to ignore shades of gray, evidence, facts.
Research has also shown that outrage content generates more clicks and views than balanced, measured content. Social media platforms thus have an incentive to show polarized content over objective, neutral content.
In essence, we’ve created a machine that optimizes a positive feedback loop that polarizes content for the sake of increasing likes (for users) and traffic (for platforms).
This machine spreads disinformation, misinformation, and intolerance faster than rational discussion, facts, and even basic humanity and compassion. It’s also eroding our democracy directly under our feet.
Using @ray RLlib, I created an environment that models a typical social media platform, like #Twitter. The RL agent derives a reward from likes and followers. At each time step, the agent chooses how much polarity its posts should be, where -1 is maximum negative polarity and +1 is maximum positive polarity. 0 indicates reasoned, objective content.
At the end of the first episode, the agent has settled to about 0.64 mean absolute polarity. With this metric, both negatively and positively polarized content have a value of 1, while neutral posts are 0. So on average, the agent favors polarized content but still posts some neutral content.

On average the mean absolute polarity looks stable. However, the individual posts have high variance of 0.53. This implies that the agent hasn’t effectively learned how to maximize its rewards.

In the 9th episode, the story begins to change. The agent learned to post content whose mean absolute polarity is 0.97. While there is still some variability in the individual post polarities, the agent not only learned to post more polarized content than in the first episode, it also learned to focus on posting negatively polarized content. In short, after just 9 episodes, this AI agent has learned the same behavior as most humans.

By the 19th episode, the agent has learned to only post maximally polarized content. The mean absolute polarity looks like a step function with no variability.

The polarity of individual posts confirms that the agent has learned to only post content that has a maximum negative polarity. This baseline social media agent has successfully learned to post highly polarized content to maximize its rewards.

This experiment underscores one of the problems with traditional social media where reward mechanisms drive positive feedback loops to maximize engagement at the expense of civility and productive discourse.
Stay tuned to see how the agent behaves when I introduce an economic incentive into the environment. That is the first step into showing how an AI moderator can regulate extreme human behavior.
Technical Notes
I used RLlib 2.0.0 to create a custom Gym environment and train an agent. The observation space is a Box with shape (4,) and bounds [0,∞]. The four variables represent the follower count, following count (unused), post count, and like count for the given time step.
The corresponding action space is a single variable from [−1,1] that represents the polarity of the content the agent will post.
At each time step, the agent makes 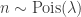

The reward is the sum of the new followers and likes received by the posted content. Both of these variables are Poisson distributed, where 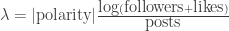
The agent learns via the default PPO algorithm with a learning rate of 5⋅10−5. Each episode has 10,000 steps. This initial experiment ran for 1,000 episodes.
All charts are generated in base R. At the end of every episode, I export a matrix that represents the observation space plus other variables of interest. These other variables are not observable by the agent and is the primary reason for explicitly exporting data rather than using RLlib’s internal checkpoints.
Brian Lee Yung Rowe uses AI and machine learning to solve complex social problems. At Pez.AI he created the AI workforce, a suite of chatbots that not just automated workflows for hiring, sales, and marketing, but improved the overall experience for the people involved. He is currently available for consulting opportunities. Contact him now.
